Většina firemních AI chatbotů je k ničemu. Postavil jsem řešení, které funguje
V posledním roce se téměř každá firma pokusila postavit vlastního AI chatbota nad svými daty. Výsledek? Většinou zklamání. Chatboti si vymýšlejí, odpovídají obecně, nebo nedokážou najít klíčové informace. Problém není v AI, ale ve špatné architektuře.
Představte si, že pošlete do firemního archivu nezkušeného brigádníka. Dostane za úkol najít odpověď na složitou otázku. Pravděpodobně popadne prvních pět šanonů, které mu přijdou pod ruku, prolistuje je a řekne: „Odpověď je asi někde tady.“ To je přesně to, co dělá většina dnešních RAG (Retrieval-Augmented Generation) systémů.
A teď si představte, že do stejného archivu pošlete zkušeného seniorního analytika. Nejdříve si vaši otázku rozloží na několik podotázek, aby přesně věděl, co hledat. Pak systematicky projde relevantní sekce, najde konkrétní dokumenty, porovná informace, ověří si fakta a na konci vám předloží stručný, přesný a zdroji podložený souhrn.
Rozhodl jsem se postavit AI systém, který pracuje jako tento seniorní analytik. Nazval jsem ho „AI Context Agent“.
Případová studie AI: Jak se zeptat na nový stavební zákon
Abych otestoval schopnosti systému na něčem skutečně složitém, „nakrmil“ jsem ho kompletním textem nového stavebního zákona (č. 283/2021 Sb.) – stovek stran hustého právního textu, ve kterém je téměř nemožné se rychle zorientovat.
Pak jsem mu položil typickou otázku, kterou řeší tisíce lidí:
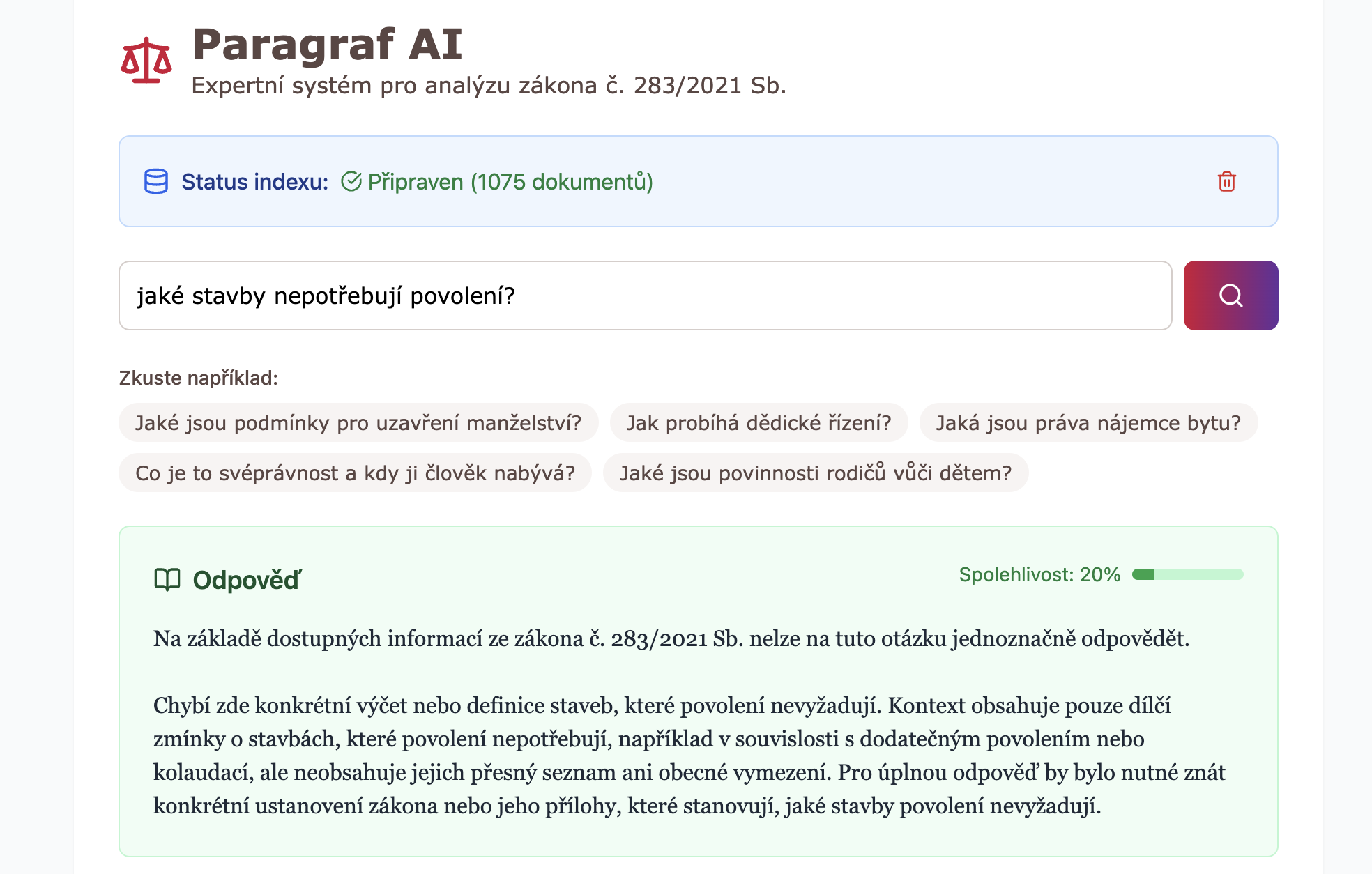
Otázka:„Stavím na zahradě malou kůlnu na nářadí o rozměrech 4×5 metrů. Potřebuji na to povolení?“
Jak by odpověděl běžný AI chatbot
„Podle zákona nepotřebujete povolení na drobné stavby. Drobná stavba je definována v zákoně. Pro více informací se obraťte na stavební úřad.“
Tato odpověď je sice technicky správná, ale naprosto k ničemu. Neodpovídá na klíčovou otázku – je moje kůlna drobná stavba?
Špatně by byla i odpověď nedokončeného RAG systému, kterému chybí klíčové komponenty a má přísný system prompt pro model (což se mi stávalo při zvolení jednoduché ChromaDB):
„Na základě dostupných informací nelze na tuto otázku jednoznačně odpovědět.„
Jak odpověděl můj AI Context Agent (RAG)
„Ne, na stavbu malé kůlny o rozměrech 4×5 metrů (20 m2) na zahradě povolení nepotřebujete. + za jakých podmínek“
Tato odpověď je přesná, srozumitelná, akční a hlavně – podložená konkrétními citacemi. Je to výsledek, který má reálnou hodnotu.
Pohled pod kapotu: 8 rozhodnutí, která dělí průměrný RAG od špičkového
Dostat se k takto přesné odpovědi není náhoda. Je to výsledek série strategických rozhodnutí v architektuře systému. Zde je 8 klíčových výzev, které jsem musel vyřešit:
1. Kvalita dat na prvním místě: Základem všeho je perfektní vstupní text. Místo abych jen zkopíroval text zákona, musel jsem napsat vlastní parser, který z webu extrahuje pouze čistý text a zachová jeho přirozenou strukturu podle paragrafů. Bez čistých dat je i nejlepší AI bezmocná.
2. Game-changer jménem Reranking: Běžné vektorové vyhledávání je jako rybaření se širokou sítí, chytíte spoustu ryb, ale i spoustu bahna. Proto jsem přidal druhou vrstvu: reranker. Ten vezme 20-30 potenciálně relevantních paragrafů a jako lidský expert je znovu přečte a seřadí. Do finální odpovědi se tak dostane jen 5 nejlepších zdrojů. To je rozdíl mezi průměrnou a skvělou odpovědí.
3. Optimální velikost chunků: Proč dělit text na kousky o velikosti 600 znaků a ne třeba 5000? Je to kompromis. Větší chunky dávají AI více kontextu, ale jsou dražší na zpracování a mohou obsahovat příliš mnoho šumu. Menší chunky jsou levnější a rychlejší, ale mohou ztratit důležité souvislosti. Velikost kolem 600-1000 znaků se ukázala jako ideální rovnováha mezi kvalitou, cenou a rychlostí.
4. Volba správného modelu (GPT-4-1 pro maximální přesnost): Pro finální generování odpovědi je klíčové použít ten nejlepší dostupný model pro daný účel, ale ne zase na úkor příliš vysokých nákladů.
Zvolil jsem GPT-4.1, protože jeho schopnost hlubokého uvažování a precizního následování komplexních instrukcí je pro citlivé právní texty naprosto zásadní. Zatímco rychlejší modely mohou stačit pro dílčí úkoly, finální syntéza vyžaduje tu nejvyšší kvalitu. Je to jako si na finální revizi smlouvy najmout toho nejzkušenějšího právníka v kanceláři.
Jasně ještě lepší by bylo použít třeba uvažovací více krokový model typu o3, ale to bych se já (nebo klient) nedoplatil. Případně to hnát přes nějaký lokální model na vlastním železe, ale zase budete řešit, že musíte mít dostatečně výkonný hardware.
Nepoužívám však pouze jeden model. Kvůli rychlost a cenám mám kombinaci agentů následující:
GPT-3.5-turbo – pro entity extraction při budování grafu
GPT-4o-mini – pro query Translator agent
GPT-4.1 – pro generator agent
5. Evoluce promptu: Můj první prompt byl jednoduchý: „Odpověz na otázku na základě kontextu a cituj správně paragrafy.“ Výsledky byly průměrné. Finální prompt je detailní soubor pravidel, který AI nařizuje, jak se má chovat: jak citovat, jak přiznat nevědomost, jak strukturovat odpověď. Kvalita RAG systému je z 50 % o datech a z 50 % o mistrovsky napsaném promptu.
6. Optimalizace latence a ceny: Aby systém odpovídal rychle a levně, používám několik triků: menší a rychlejší model pro embedding (text-embedding-3-small), neo4j cloud a efektivní reranker, který zmenší množství dat posílaných do nejdražšího LLM. Cílem je, aby 90 % práce odvedly levnější komponenty a jen finální syntézu dělal ten nejdražší expert.
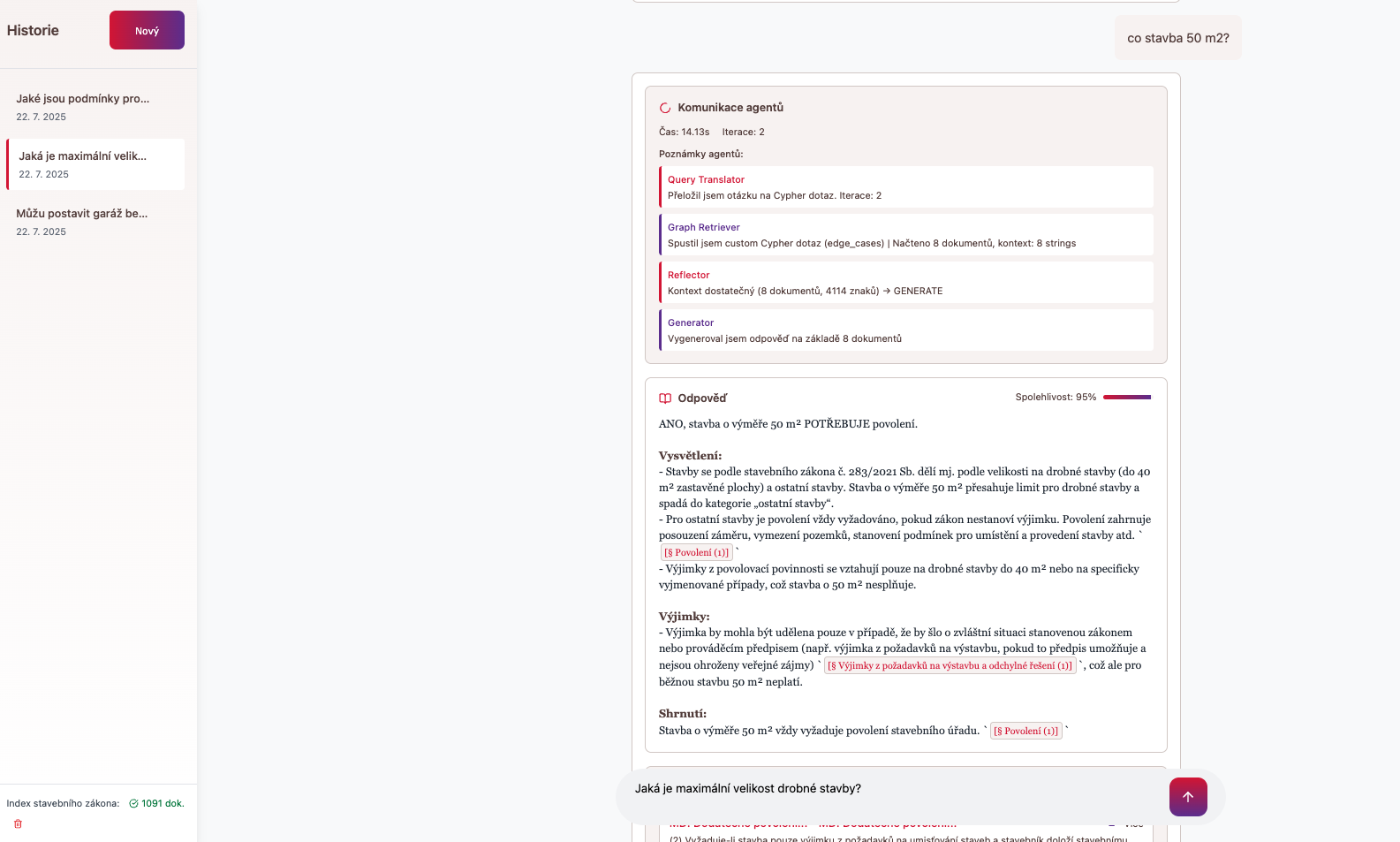
7. Překlenutí sémantické propasti (Hybridní GraphRAG s Neo4j): Během testování jsem narazil na limitaci všech běžných RAG systémů. Dotaz „stavba bez povolení“ nedokázal spolehlivě najít text o „drobné stavbě“, ačkoliv jsou logicky propojené. Vektorová databáze je skvělá na hledání sémantické podobnosti, ale nechápe vztahy. Proto jsem systém povýšil na hybridní model a přidal znalostní graf v Neo4j. Ten funguje jako mozek, který mapuje logické vztahy.
Náš systém se tak nejprve zeptá grafu na logické souvislosti a teprve poté provede cílené vektorové vyhledávání. Je to kombinace kompasu (Neo4j) a sonaru (vektory), která zaručuje, že najdeme vždy ten správný kontext.
Původní ChromaDb nedokázala najít požadavaný kontextVylepšená odpověď s pomocí neo4j a LanggraphVylepšené rozhraní chatu v React
8. Od montážní linky k přemýšlejícímu agentovi (LangGraph): Většina RAG systémů funguje jako jednoduchá montážní linka (technicky LangChain): dotaz -> hledání -> odpověď. Co když je ale první hledání neúspěšné? Linka se zastaví. Proto jsem pro řízení celého procesu použil LangGraph. Ten nám umožňuje postavit skutečného autonomního agenta, který umí pracovat v cyklech. Pokud první vyhledávání nenajde dostatečný kontext, agent se sám rozhodne, přeformuluje dotaz a zkusí to znovu. Je to rozdíl mezi strojem, který plní příkazy a expertem, který přemýšlí a iteruje, dokud nenajde správnou odpověď.
Od chatbota k expertnímu systému
Většina firem dnes staví AI „brigádníky“. Jsou levní, rychlí, ale jejich práce je povrchní a často chybná. Budoucnost ale patří firmám, které si dokážou postavit AI „seniorní experty“, systémy, které přemýšlejí, analyzují a poskytují přesné, daty podložené vhledy.
Tento projekt je ukázkou, že s promyšlenou architekturou a správnými nástroji je možné takový systém postavit. Není to magie, je to inženýrství.
Technickou dokumentaci a datovou pipeline pro ukázku najdete na mém GitHubu.
Tímto článkem také otevírám svůj seriál AI chatboti: konkrétní ukázky veřejných chatbotů, kteří buď nefungují správně, nebo ani neexistují a já je realizuji.Pokud se vám články líbí, nezapomeňte odebírat můj newsletter níže.