

V minulých dílech jsme optimalizovali výkon a náklady. Nyní se vrátíme k samotnému jádru inteligence našeho systému. Kdybych měl vybrat jednu jedinou technologii, která v posledním roce posunula hranice toho, co AI dokáže v byznysu, byl by to GraphRAG.
Toto je sedmý díl seriálu Agentní RAG chatbot, kde krok za krokem rozebírám, jak správně postavit celou architekturu a čemu se naopak vyhnout. Postupně zde najdete odkazy na všechny díly, které si časem můžete přečíst.
Představte si, že čtete detektivku. Běžný RAG systém (vektorové vyhledávání) je jako čtenář, který si pamatuje jednotlivé odstavce. Když se zeptáte na vraha, najde vám všechny odstavce, kde se o vrahovi píše.
Ale GraphRAG? To je čtenář, který si na zeď nalepil fotky všech postav, propojil je červenými nitkami a chápe, kdo s kým mluvil, kdo koho nenávidí a kdo měl motiv. Nezná jen text. Zná příběh a vztahy.
V tomto díle se podíváme na to, jak tuto červenou niť postavit v praxi pomocí databáze Neo4j a proč je to pro vaše firemní data revoluce.
Proč vektory nestačí: Slepota k souvislostem
Vektorové databáze jsou úžasné v hledání sémantické podobnosti. Pokud hledáte smlouvu o dílo, najdou vám dokumenty, které vypadají jako smlouva o dílo. Ale v reálném byznysu to nestačí.
Představte si dotaz: „Jaké riziko nám hrozí u dodavatelů, kteří jsou propojeni s firmou v insolvenci?“
Vektorový systém selže. Nenajde dokument, který by obsahoval všechna tato slova najednou. Informace je totiž roztříštěná:
- Dokument A říká, že „Firma X je náš dodavatel“.
- Dokument B říká, že „Firma X je dceřinou společností Firmy Y“.
- Dokument C (z obchodního rejstříku) říká, že „Firma Y je v insolvenci“.
Žádný z těchto dokumentů sám o sobě neodpovídá na otázku. Ale pokud je spojíme, odpověď je jasná. A přesně to dělá GraphRAG.
Technická implementace: Jak stavím graf v Neo4j
Přechod na GraphRAG vyžaduje změnu myšlení. Místo abychom text jen rozsekali a uložili, musíme ho modelovat. Zde je můj osvědčený postup, jak to dělám v praxi:
- Definice ontologie (Schéma grafu): Než napíšu řádek kódu, musím si nakreslit, jaká data mám a jak spolu souvisí. Pro firemní dokumentaci to může vypadat takto:
- Uzly (Nodes):
Dokument,Osoba,Firma,Projekt,Téma. - Vztahy (Relationships):
(:Osoba)-[:NAPSALA]->(:Dokument),(:Dokument)-[:ZMIŇUJE]->(:Projekt),(:Projekt)-[:PATŘÍ_POD]->(:Firma).
- Uzly (Nodes):
- Extrakce entit a vztahů (LLM jako analytik): Zde využívám sílu modelu GPT-4.1. Místo abych ho nechal jen generovat text, použiji ho jako extraktor. Pošlu mu text dokumentu a instrukci: „Najdi v textu všechny firmy a projekty a vytvoř mezi nimi vztahy podle definované ontologie.“ Výstupem je strukturovaný JSON, který přesně popisuje, kdo je kdo.
- Hybridní indexace: Toto je mé tajné koření. Do databáze Neo4j neukládám jen graf. Ukládám tam i vektorové embeddingy textových chunků. Každý uzel
Dokumentmá tedy svou textovou část (pro vektorové hledání) i své vztahové vazby (pro grafové hledání).
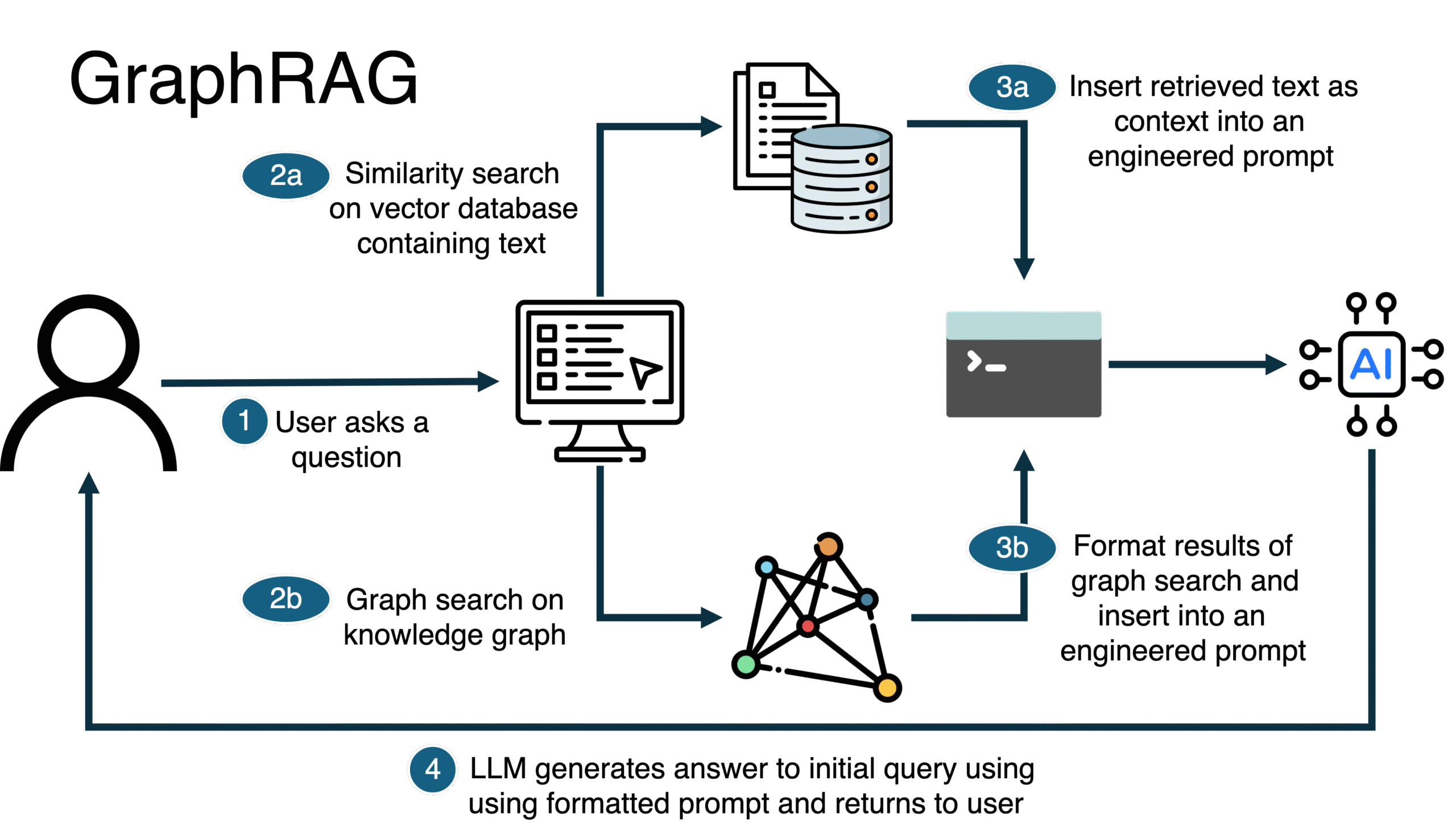
Příklad z praxe: Odhalení skrytých rizik ve smlouvách
U jednoho z mých klientů jsme řešili analýzu tisíců starých smluv. Cílem bylo najít ty, které odkazují na již neplatné normy. Běžný RAG našel smlouvy, kde se vyskytovalo číslo normy. Ale to bylo málo.
Nasazením GraphRAGu jsme vytvořili model, kde:
- Uzel
Smlouvaměl vztah[:ODKAZUJE_NA]k uzluNorma. - Uzel
Normaměl vztah[:NAHRAZENA_KÝM]k uzluNová_Norma. - Uzel
Nová_Normaměl vlastnostplatnost: true.
Díky tomu jsme mohli položit dotaz, který by v běžném vyhledávání nebyl možný: „Najdi mi všechny smlouvy, které odkazují na normu, jež byla nahrazena jinou normou, která je dnes platná.“ Systém během vteřiny vrátil přesný seznam rizikových smluv, aniž by v nich slovo „neplatná“ muselo být explicitně napsáno. Odvodil si to ze vztahů.
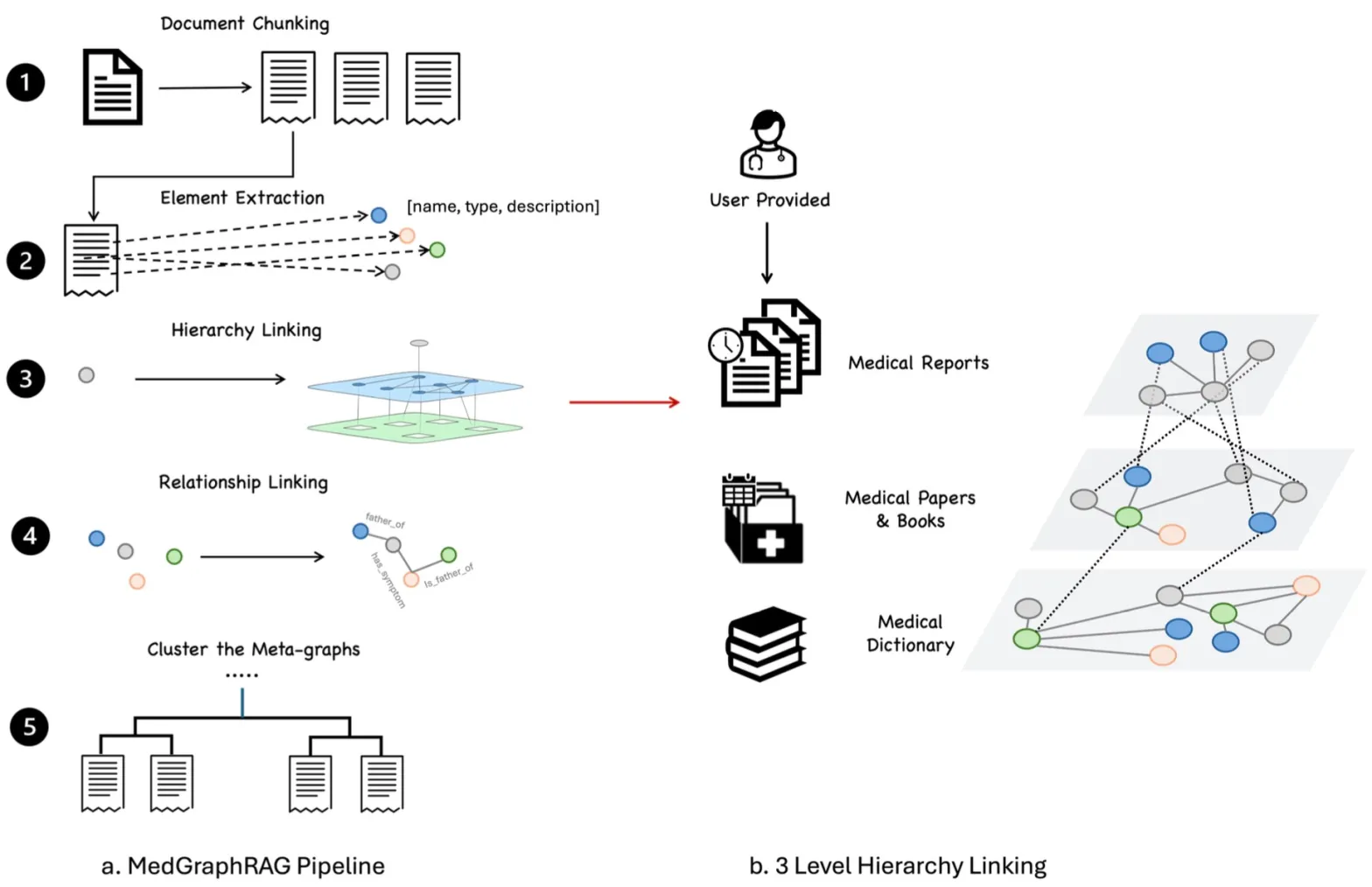
Nahlédnutí pod kapotu: Architektura hybridního vyhledávání
Mnoho RAG systémů selhává na tom, že se spoléhají na jediný mechanismus. Já ve svých projektech stavím robustní pipeline, která kombinuje sílu grafů, vektorů a fulltextu do jednoho harmonického celku. Zde je pohled na to, jak takový systém reálně funguje.
1. Centrální mozek: Neo4j jako hybridní úložiště
Místo abychom měli data roztříštěná v několika databázích (jedna pro vektory, druhá pro metadata), používám Neo4j jako centrální hub.
- Uzly (Nodes): Reprezentují vše od dokumentů a jejich částí (
DocumentChunk), přes produkty a kategorie až po klíčová slova. - Vektory: Embeddings (vytvořené modelem
text-embedding-3-small) ukládám přímo k uzlům v grafu. Díky nativnímu HNSW indexu v Neo4j je vyhledávání bleskurychlé. - Vztahy: To je ta přidaná hodnota. Definuji vztahy jako
[:SIMILAR_TO],[:DESCRIBES_PRODUCT]nebo[:BELONGS_TO_CATEGORY], které propojují nestrukturovaný text se strukturovaným byznysovým kontextem.
2. Pětikrokový RAG Pipeline
Když uživatel položí dotaz, nespustí se jen jednoduché hledání. Rozběhne se sofistikovaný proces:
- Query Embedding: V prvním kroku převedeme uživatelův dotaz na 1536-dimenzionální vektor pomocí OpenAI API. Zároveň kontrolujeme cache, abychom neopakovali výpočet pro stejné dotazy.
- Hybrid Search: Systém spustí tři paralelní strategie. Vektorové hledání najde sémanticky podobné texty. Fulltextové hledání zachytí přesná klíčová slova. A grafová traversace najde související dokumenty přes vztahy (např. „Najdi dokumenty, které souvisí s produktem zmíněným v dotazu“).
- Advanced Reranking: Výsledky ze všech tří strategií se spojí a seřadí pomocí komplexního scoring algoritmu. Ten nebere v potaz jen podobnost, ale i byznysovou prioritu. Například dokumenty typu „FAQ“ nebo „Informace z webu“ dostávají speciální boost, protože často obsahují přímé odpovědi. Naopak obecné PDF soubory mohou dostat penalizaci, pokud existuje lepší zdroj.
- Context Enrichment: Pro ty nejlepší dokumenty systém načte nejen nalezený úryvek, ale kompletní kontext (všechny související chunky). Díky multi-hop inference dokáže odvodit vztahy i přes dva skoky v grafu (např. Dokument -> Kategorie -> Související Kategorie -> Jiný Dokument).
- AI Generování: Teprve takto obohacený a vyčištěný kontext se pošle modelu GPT-4.1, který vygeneruje finální odpověď.
Výsledkem je systém, který nehledá jen slova, ale chápe význam. Dokáže odpovědět na dotaz „Jaké jsou varianty produktu X?“, i když slovo „varianta“ v textu není, protože si to odvodí ze vztahu [:VARIANT_OF] v grafu. To je rozdíl mezi vyhledávačem a znalostním expertem.
Jaký je přínos
Naučili jsme se, že data nejsou plochá. Mají strukturu a vztahy, které nesou obrovskou informační hodnotu. GraphRAG nám umožňuje tuto hodnotu odemknout.
Byznysový přínos je transformativní. Přecházíme od vyhledávání informací k odhalování znalostí. Systém dokáže najít souvislosti, které člověk přehlédne, upozornit na rizika, která nejsou na první pohled vidět, a poskytnout odpovědi, které jsou podložené logikou, ne jen pravděpodobností.
Je to náročnější na implementaci? Ano. Stojí to za to? Pokud chcete systém, který skutečně přemýšlí v kontextu vaší firmy, tak absolutně.
V příštím, osmém díle se podíváme na to, jak tento mozek rozpohybovat. Ukážeme si, jak postavit tým spolupracujících AI agentů pomocí frameworku LangGraph.
Díly seriálu
- Agentní RAG chatbot 1) Strategie zpracování dat pro RAG
- Agentní RAG chatbot 2) Výběr a architektura databáze
- Agentní RAG chatbot 3) Umění relevance a ladění RAG
- Agentní RAG chatbot 4) Jak napsat perfektní system prompt
- Agentní RAG chatbot 5) Výběr správného motoru a strategie
- Agentní RAG chatbot 6) Pokročilá optimalizace výkonu a nákladů
- Agentní RAG chatbot 7) Síla vztahů a průvodce implementací graphRAG
- Agentní RAG chatbot 8) Tým expertů a agentních systémů v LangGraph
- Agentní RAG chatbot 9) Zabezpečení dat v AI aplikacích
- Agentní RAG chatbot 10) Ladění systému v reálném provozu
- Agentní RAG chatbot – Bonus: Případová studie


