

Vítejte v cílové rovince. V předchozích devíti dílech o Agentním RAG systému jsme prošli cestu od prázdného papíru až po sofistikovaný tým AI agentů chráněný digitální pevností. Náš AI systém je hotový. V testovacím prostředí odpovídá skvěle, zná naše směrnice a nepouští ven tajná data.
Toto je desátý díl seriálu Agentní RAG chatbot, kde krok za krokem rozebírám, jak správně postavit celou architekturu a čemu se naopak vyhnout. Postupně zde najdete odkazy na všechny díly, které si časem můžete přečíst.
Mnoho firem si v této fázi otevře šampaňské, nasadí systém na web a jde slavit. A to je fatální chyba.
Spuštění AI systému do produkce není konec projektu. Je to začátek nové disciplíny, které říkáme LLMOps, neboli provoz velkých jazykových modelů. Je to jako když vychováte dítě a pošlete ho poprvé samotné do školy. Můžete ho připravit, jak nejlépe umíte, ale teprve tam se ukáže, jak si poradí s realitou.
Dnes se podíváme na to, co vás čeká první den po spuštění, a jak zajistit, aby se váš systém nezhoršoval, ale naopak každým dnem zlepšoval.
Šok z reality prvního dne
Připravte se na studenou sprchu. V laboratoři jsme AI systém testovali na hezkých, jasných otázkách typu „Jaká je maximální výše příspěvku na stravování“.
Reální uživatelé se takhle neptají. Reální uživatelé dělají překlepy, používají slang, mění téma uprostřed věty nebo jsou prostě naštvaní a sarkastičtí.
Příklad z praxe: Náš AI systém jsem ladil pro tzv. small talk, abychom zbytečně neplýtvali časem a tokeny na spouštění RAG systému při banálních dotazech. Náš systém uměl reagoval na pozdravy typu Ahoj, čau, dobrý den, atd. Ale když uživatel zadal Ahoj se smajlíkem, systém najednou nerozeznal, že se stále jedná o small talk. Je to přesně ten typ dotazu, který vás běžně nenapadne při vývoji i testování.
Vaše krásná 95% úspěšnost z testů se první den propadne třeba na 70 %. To není selhání. To je normální stav.
Žádný plán nepřežije první kontakt s „nepřítelem“, v našem případě s uživatelem. Důležité není to, že systém dělá chyby, ale to, jak rychle je dokážeme detekovat a opravit.
Monitorování: Co nevidíte, to neřídíte
U klasického softwaru sledujeme, jestli server běží a kolik má paměti. U AI systému musíme sledovat kvalitu myšlení. Potřebujeme vidět dovnitř mozku našich agentů v reálném čase.
Pro své klienty stavím produkční dashboardy, které sledují tři klíčové metriky:
- Latence a Cena: Jak dlouho trvá vygenerování odpovědi a kolik nás stála na poplatcích za API (např. OpenAI). Pokud se průměrná doba odpovědi začne povážlivě navyšovat, víme, že máme problém s výkonem databáze, špatným modelem nebo příliš složitým grafem agentů.
- Zpětná vazba uživatelů: Klasické palce nahoru a dolů u každé odpovědi + komentáře uživatelů. To je absolutní minimum. Díky tomu máme neustálou zpětnou vazbu v databázi a můžeme v reálném čase hned chyby opravit.
- Hloubková analýza tras (Tracing): Toto je nejdůležitější nástroj pro vývojáře. Umožňuje nám u každé špatné odpovědi zpětně přehrát celý myšlenkový proces agenta. Vidíme, jaká data našel v GraphRAGu, proč se rozhodl tak, jak se rozhodl, a kde přesně udělal chybu. Bez toho jste slepí.
Jak chyby měnit ve zlato
Největší hodnotou provozu nejsou ty odpovědi, které se povedly. Největší hodnotou jsou ty, které se nepovedly.
Každý palec dolů od uživatele je dar. Je to signál, že našemu modelu něco chybí. Může mu chybět dokument v databázi, může mít špatný systémový prompt, nebo může špatně chápat souvislosti v grafu.
V praxi zavádíme proces, kterému říkáme Human-in-the-loop Feedback Loop:
- Uživatel označí odpověď jako špatnou.
- Tato konverzace se uloží do speciální fronty pro lidské experty.
- Jednou týdně si váš doménový expert, například vedoucí zákaznické podpory, sedne k této frontě. Přečte si špatnou odpověď AI a napíše správnou odpověď.
- Tato opravená dvojice Otázka -> Správná odpověď se stává součástí takzvaného Zlatého datasetu.
- Tento dataset používáme k přetestování systému nebo dokonce k jemnému doladění (fine-tuning) modelu.
Tímto způsobem vytváříme datový setrvačník. Čím více systém používáte a čím více chyb dělá, tím chytřejším se stává, pokud ty chyby aktivně opravujete. Z pasivního nástroje se stává učící se organismus.
LLMOps jako nová firemní kompetence
Pokud to s AI myslíte vážně, nemůžete ji brát jako jednorázový IT projekt. Je to nová firemní funkce.
Stejně jako máte oddělení HR, které se stará o lidské zaměstnance, budete potřebovat procesy pro péči o ty digitální. Data stárnou, modely se mění (to, co fungovalo na GPT-4.1, nemusí fungovat na GPT-5.3) a uživatelské návyky se vyvíjí.
Udržet sofistikovaný RAG systém v chodu vyžaduje průběžnou údržbu, aktualizaci vektorových indexů a revizi promptů.
Je to investice do udržení konkurenční výhody.
Automatizovaná evaluace: Když robot kontroluje robota
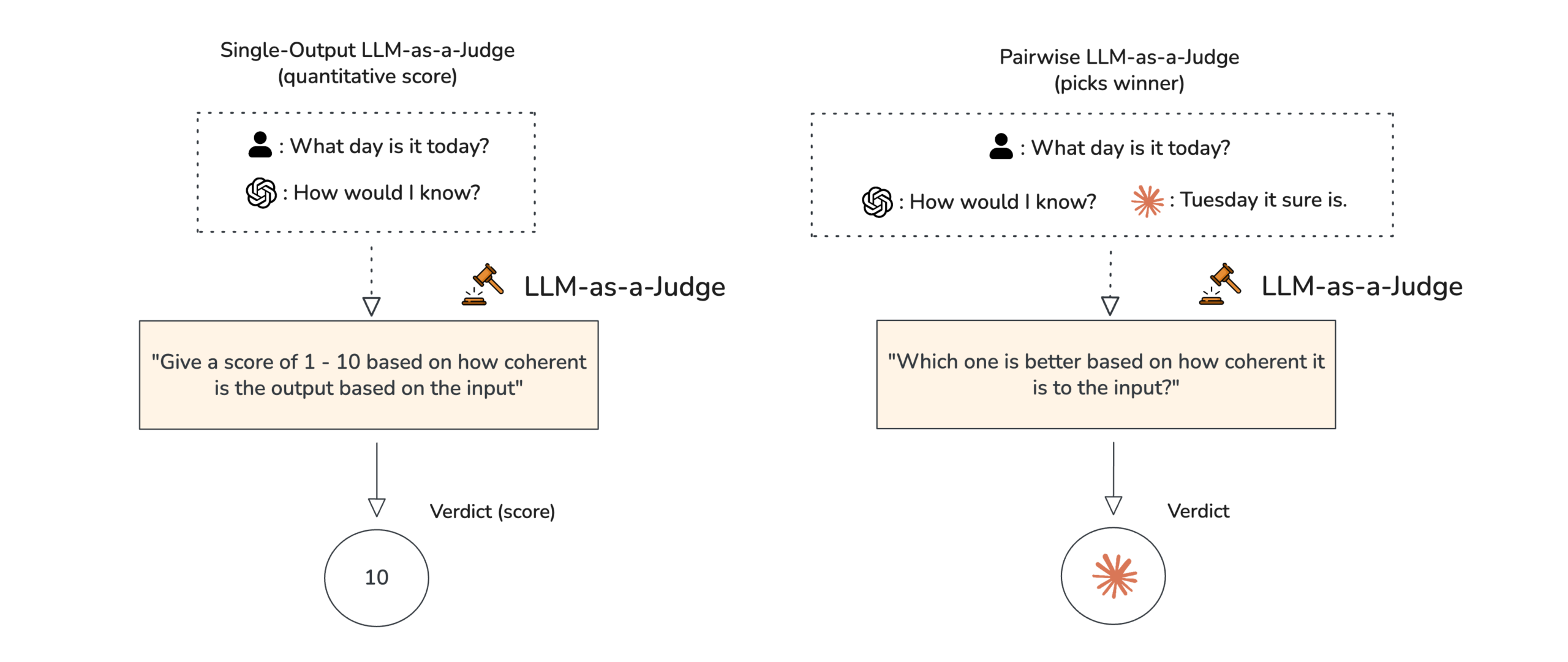
Spoléhat se jen na to, že si budete po večerech číst logy konverzací, je cesta do pekel. Při stovkách dotazů denně je to fyzicky nemožné a lidská pozornost rychle upadá. Proto do hry vstupuje automatizovaná evaluace, kde využíváme koncept zvaný LLM-as-a-Judge.
V praxi to vypadá tak, že silnější a dražší model, obvykle GPT-5 (nebo novější), funguje jako neúprosný učitel. Každou noc automaticky projde konverzace z celého dne a oboduje je. Dostane k dispozici otázku uživatele, data nalezená v databázi a finální odpověď agenta. Následně vyhodnotí, zda odpověď dává smysl, zda věrně vychází z podkladů a zda agent nehalucinuje.
Výsledkem je, že ráno nemáte na stole jen hromadu textu, ale jasný graf kvality. Pokud po aktualizaci systému klesne průměrné skóre přesnosti z 95 % na 88 %, systém vás okamžitě upozorní. Díky tomu odhalíte regresi kvality dříve, než si toho všimnou naštvaní zákazníci, a můžete klidně spát s vědomím, že kvalitu hlídá neúnavný stroj.
Odvaha k inovaci
Gratuluji. Pokud jste dočetli až sem, máte nyní lepší přehled o architektuře moderních AI systémů než 99 % manažerů na trhu.
Prošli jsme cestu od jednoduchého vyhledávání až po autonomní agenty a jejich provoz. Viděli jste, že to není magie, ale komplexní inženýrská disciplína.
Možná vás ta složitost vyděsila. To je dobře. Znamená to, že chápete rizika a nebudete naivní. Ale nenechte se strachem paralyzovat.
Ti, kteří tuto cestu podstoupí dnes a prokoušou se porodními bolestmi zavádění AI, budou mít za dva roky náskok, který už konkurence nedožene. Nebudou mít jen chatboty. Budou mít institucionální paměť a procesy, které škálují nekonečně rychleji než nábor nových lidí.
Tímto náš technický seriál končí. Ale protože teorie je šedá a strom života zelený, připravil jsem pro vás ještě jeden bonusový díl. V něm se podíváme na konkrétní případovou studii, kde jsme všechny tyto principy nasadili v praxi a jaké to přineslo reálné byznysové výsledky.
Děkuji, že jste četli, a přeji vám odvahu do vašich AI projektů.
Díly seriálu
- Agentní RAG chatbot 1) Strategie zpracování dat pro RAG
- Agentní RAG chatbot 2) Výběr a architektura databáze
- Agentní RAG chatbot 3) Umění relevance a ladění RAG
- Agentní RAG chatbot 4) Jak napsat perfektní system prompt
- Agentní RAG chatbot 5) Výběr správného motoru a strategie
- Agentní RAG chatbot 6) Pokročilá optimalizace výkonu a nákladů
- Agentní RAG chatbot 7) Síla vztahů a průvodce implementací graphRAG
- Agentní RAG chatbot 8) Tým expertů a agentních systémů v LangGraph
- Agentní RAG chatbot 9) Zabezpečení dat v AI aplikacích
- Agentní RAG chatbot 10) Ladění systému v reálném provozu
- Agentní RAG chatbot – Bonus: Případová studie




