

Velmi mě nadchl nový model Llama 3 od Meta v kombinaci s technologií Groq, díky které je odezva super rychlá. Takový chatbot je sám o sobě velmi fajn, ale co to rovnou vyzkoušet na vlastních nestrukturovaných datech? V tomto návodu si uděláme celou aplikace na Chainlit platformě.
Pojďme si nejprve projít jednotlivé komponenty.
Llama 3
Llama 3 je nový open source model od Meta, který se dle posledních benchmarků vyrovnává aktuálně největším a nejvýkonnějším modelům na trhu, jako je GPT-4, Claude-3 nebo Gemini. Jeho nespornou výhodou pro celou nezávislou vývojářskou komunitou je to, že je zdarma dostupný a s otevřeným kódem. Tento model má pouze 8000 tokenů kontextové okno a není multimodální. Aktuálně jsou k dispozici dva modely, jeden menší 8B a větší 70B. Časem Meta chystá mnohem výkonnější model 400 B.
Groq
Společnost Groq přišla na trh s tzv. čipy LPU, speciálně navržené pro jazykové modely. Narozdíl od CPU nebo GPU je Groq schopen mnohem rychlejší odezvy. Když si porovnáte rychlost jednotlivých modelů, tak Groq nabízí opravdu bleskovou rychlost. Aktuálně nabízí možnost volání API pro různé open source modely, včetně nejnovějších Llama modelů.
RAG
Možnost přidat do modelu dodatečné znalosti, které nemá ve svých trénovacích datech. Stačí přidat např. PDF dokument pomocí chunking, embeddings a vektorové databáze. Dokument je tedy nejprve rozdělen na menší části, následně vektorizován a uložen do databáze. Při volání modelu je poskytnut potřebný kontext pro model a ten je následně schopen odpovídat více fakticky a méně halucinovat (tj. odpovídat méně náhodně).
Chainlit
Chainlit je open-source balíček Pythonu pro vytváření produkčních aplikací. Sestavuje se velmi rychle a je zde možnost napojit další funkcionality. Nespornou výhodou je, že vám odpadá práce s nastavováním frontendu.
kód aplikace
Nyní již pojďme rovnou připravit kód.
Nejprve si připravíme virtuální prostředí ve složce aplikace na počítači.
Nainstalujeme knihovny.
pip install chainlit langchain langchain_community PyPDF2 chromadb groq
langchain-groq ollamaImportujeme knihovny.
import PyPDF2
from langchain_community.embeddings import OllamaEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain_community.chat_models import ChatOllama
from langchain_groq import ChatGroq
from langchain.memory import ChatMessageHistory, ConversationBufferMemory
import chainlit as clNastavení API klíče a model od Groq a Llama-3.
groq_api_key = "KEY"
llm_groq = ChatGroq(
groq_api_key=groq_api_key,
model_name='llama3-70b-8192'
)Začátek chatu a nahrání dokumentu.
@cl.on_chat_start
async def on_chat_start():
files = None #Initialize variable to store uploaded files
# Wait for the user to upload a file
while files is None:
files = await cl.AskFileMessage(
content="Please upload a pdf file to begin!",
accept=["application/pdf"],
max_size_mb=100,
timeout=180,
).send()
file = files[0] # Get the first uploaded file
# Inform the user that processing has started
msg = cl.Message(content=f"Processing `{file.name}`...")
await msg.send()Čtení dokumentu a následné rozdělení na chunky, vytvoření metadat.
# Read the PDF file
pdf = PyPDF2.PdfReader(file.path)
pdf_text = ""
for page in pdf.pages:
pdf_text += page.extract_text()
# Split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_text(pdf_text)
# Create a metadata for each chunk
metadatas = [{"source": f"{i}-pl"} for i in range(len(texts))]
Embedding model Nomic a vytvoření vektorové databáze Chroma.
# Create a Chroma vector store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
#embeddings = OllamaEmbeddings(model="llama2:7b")
docsearch = await cl.make_async(Chroma.from_texts)(
texts, embeddings, metadatas=metadatas
)Nastavení historie a paměti konverzace.
# Initialize message history for conversation
message_history = ChatMessageHistory()
# Memory for conversational context
memory = ConversationBufferMemory(
memory_key="chat_history",
output_key="answer",
chat_memory=message_history,
return_messages=True,
)Nastavení RAG a informování uživatele, že je systém připraven.
# Create a chain that uses the Chroma vector store
chain = ConversationalRetrievalChain.from_llm(
llm = llm_groq,
chain_type="stuff",
retriever=docsearch.as_retriever(),
memory=memory,
return_source_documents=True,
)
# Let the user know that the system is ready
msg.content = f"Processing `{file.name}` done. You can now ask questions!"
await msg.update()
#store the chain in user session
cl.user_session.set("chain", chain)Získání informace pomocí RAG a následné přidání do odpovědi uživatele.
@cl.on_message
async def main(message: cl.Message):
# Retrieve the chain from user session
chain = cl.user_session.get("chain")
#call backs happens asynchronously/parallel
cb = cl.AsyncLangchainCallbackHandler()
# call the chain with user's message content
res = await chain.ainvoke(message.content, callbacks=[cb])
answer = res["answer"]
source_documents = res["source_documents"]
text_elements = [] # Initialize list to store text elements
# Process source documents if available
if source_documents:
for source_idx, source_doc in enumerate(source_documents):
source_name = f"source_{source_idx}"
# Create the text element referenced in the message
text_elements.append(
cl.Text(content=source_doc.page_content, name=source_name)
)
source_names = [text_el.name for text_el in text_elements]
# Add source references to the answer
if source_names:
answer += f"\nSources: {', '.join(source_names)}"
else:
answer += "\nNo sources found"
#return results
await cl.Message(content=answer, elements=text_elements).send()Jakmile máme vytvořený kód v souboru app.py a nainstalovanou aplikaci Chainlit v našem virtuálním prostředí, můžeme spustit pomocí příkazu: chainlit run app.py.
Následně se spustí aplikace na adrese http://localhost:8000/.
Chatování s PDF

Přidáme dokument PDF a jakmile je načten, můžeme následně zahájit chat.
Můžeme se zeptat, o čem je dokument.
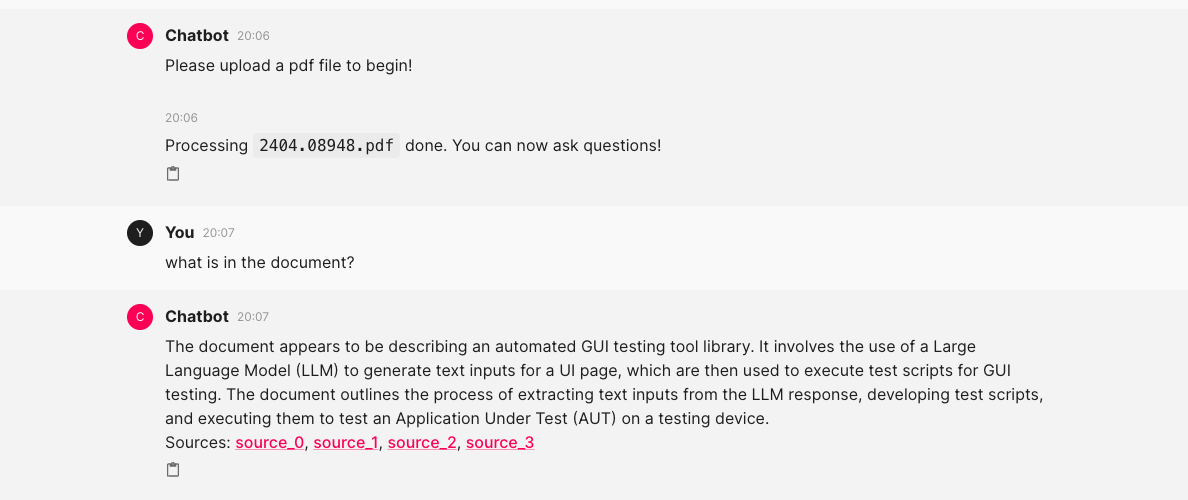
Nechat si vypsat hlavní body a závěry studie.

Rozkliknout si zdroje tvrzení a zkontrolovat, zda odpověď koresponduje s poskytnutým dokumentem.
Zde můžete vidět rychlost odpovědi. Oproti jiným modelům je opravdu bleskurychlá.
Zhodnocení
Jsem velmi nadšen z rychlosti odezvy technologie Groq. Když víte, jak dlouho se čeká na odezvu jiných modelů (zejména třeba chatGPT), tak vám musí tato latence připadat jako z jiného světa. Zatím samozřejmě nemáme k dispozici více jazyků (jako např. specifická čeština) a musíme se spokojit pouze s angličtinou a několika dalšími hlavními jazyky, ale obecně se dá říct, že open source model Llama 3 nabízí úplně nové možnosti a můžeme se těšit na mraky nových aplikací a případovek. Spojení Groq + Llama 3 + RAG na vlastní datech je za mě začátek, který vypadá velmi slibně. Těším se na propojení s dalšími nástroji, jako např. search, data interpreter nebo SQL databáze. A co je na tom nejlepší? Takto skvělý open source model opět přinutí big tech company znovu snížit ceny a přidat další lepší a výkonnější modely.




