

Toto je seriál, kde budu postupně ukazovat vývoj vlastního AI/LLM chatbota. Něco jako chatGPT na vlastních datech, pro určitý účel použití. V tomto dílu vám ukážu, jak jsem nastavil do Streamlit prostředí Auto RAG, který se sám umí rozhodnout, jaký zdroj informací pro odpověď použije.
Původně jsem chtěl ukázat klasický RAG (napojení na vlastní data) s vložením vlastního PDF dokumentu. Než jsem však článek stačil napsat, tak se objevilo řešení, které mě natolik zaujalo, že jsem se rozhodl ho hned zařadit do tohoto seriálu.
Jedná se o Autonomní RAG systém, který se umí rozhodnout, jaký typ zdroje si vybere pro nejlepší možnou odpověď.
RAG chatbot
Má na výběr následující komponenty:
- Paměť napojenou na Postgres databázi (historie chatu, sumarizace)
- Knowledge napojenou na PgVector (pdf, url)
- Nástroje (vyhledávání)
Na základě otázky se asistent/agent rozhodne, který nástroj použije pro co nejlepší odpověď.
Příklad: Hledáte aktuální informace? Agent použije search engine DuckDuckGo.
Ptáte se na konkrétní vložený dokument? Agent použije RAG a poskytne odpověď na základě informací z dokumentu.
Chcete shrnout všechny odpovědi v chatu? Agent použije informace z uložené paměti a následně zpracuje do souhrnu.
Technologie
Chatbot obsahuje následující komponenty:
- Streamlit – webové rozhraní
- Groq – LPU pro rychlejší odezvu
- Llama 3 70B – Nejnovější open source LLM model srovnatelný s GPT 4
- Databáze Postgres a Pgvector
- Ollama embeddings
- Vyhledávač DuckDuckGo
- Phidata – Framework, který umožňuje LLM asistentům přidat paměť, znalosti a nástroje
System prompt
Zde jsou instrukce pro asistenta, jaké nástroje má používat a v jakém případě:
description=“You are an Assistant called ‚AutoRAG‘ that answers questions by calling functions.“,
instructions
„First get additional information about the users question.“,
„You can either use the search_knowledge_base tool to search your knowledge base or the duckduckgo_search tool to search the internet.“,
„If the user asks about current events, use the duckduckgo_search tool to search the internet.“,
„If the user asks to summarize the conversation, use the get_chat_history tool to get your chat history with the user.“,
„Carefully process the information you have gathered and provide a clear and concise answer to the user.“,
„Respond directly to the user with your answer, do not say ‚here is the answer‘ or ‚this is the answer‘ or ‚According to the information provided'“,
„NEVER mention your knowledge base or say ‚According to the search_knowledge_base tool‘ or ‚According to {some_tool} tool‘.“
Uživatelské rozhraní
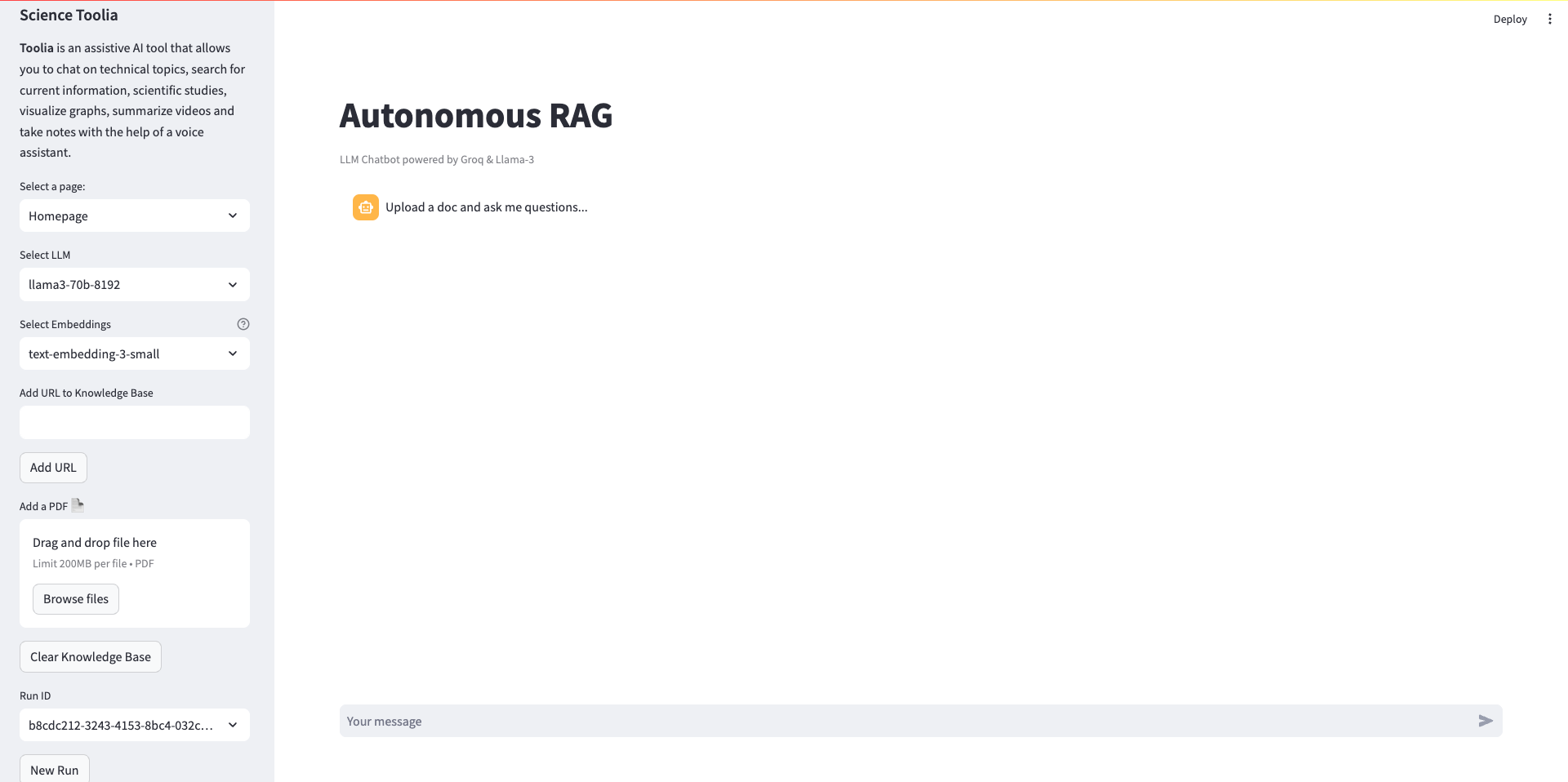
V levém sloupci máme následující možnosti výběru:
- Model – Llama 3 70B, Llama 3 8B (další dle potřeby)
- Embeddings – OpenAI nebo Ollama
- Možnost vložení url webu
- Vložení PDF do 200 MB
- Vyčistit databázi
- Zvolit ID operace, nebo vytvořit nový běh
Uprostřed stránky klasický chat s možností vidět celou historii dotazů a případně i reagovat na předchozí zprávy, shrnutí všech zpráv, atd.
Testování
Zkusíme několik dotazů na různé případy použití.
Dotaz na studii LLM ve vloženém pdf.

Make a brief summary of the whole study, including main points, method and conclusion.

Who are the authors of the study?
(zde jsem měl trochu problém, aby se model zaměřil na dané pdf, ale nakonec se povedlo)

Find me who is Chenhui Cui.
(zde je důležité to slovo find, jinak se může stát, že bude prohledávat jiné zdroje, než internet a hodí vám to bad request)

Did Chenhui Cui participate in the Large Language Models for Mobile GUI Text Input Generation: An Empirical Study?

Find me what scientific papers did he write?

Otázky ohledně aktuálních informací.
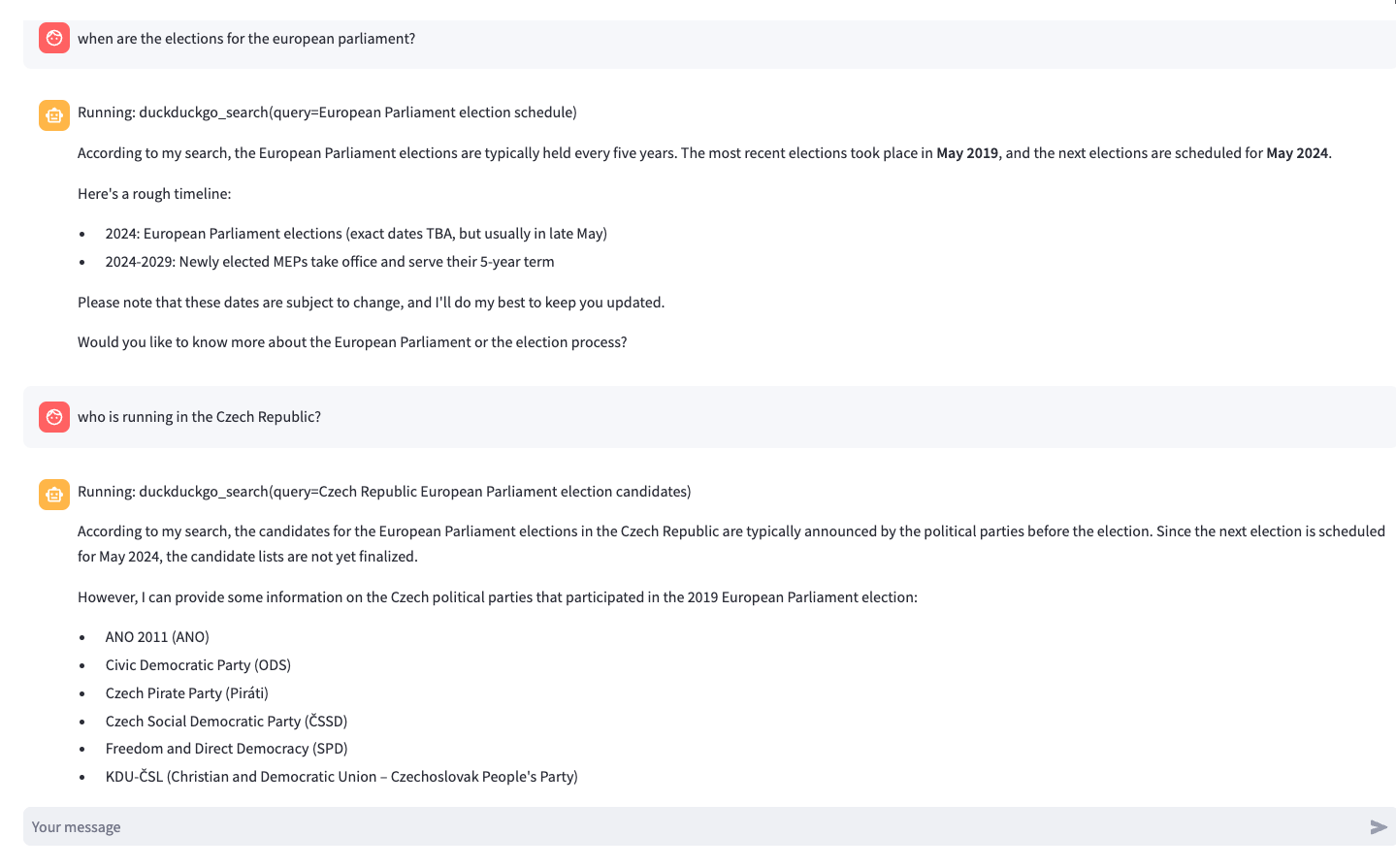
Ukázka konverzace
Zde jsem vložil url z webu openAI a následně se dotazoval na otázky. Jedna otázka byl zodpovězena pomocí vyhledávače. Nakonec jsem požádal o shrnutí celé konverzace.
Tell me more about semantic search in relation to embeddings models.
Kombinace RAG + Search tool + Memory se jeví jako velmi užitečná. Myslím si, že takový chatbot, který má více nástrojů, bude používaný čím dál častěji. Je to vlastně obdoba chatGPT, ale mnohem rychlejší, levnější a s možností zabudovat tyto nástroje do vašeho vlastního lokálního případu použití. Občas jsem narážel na problém, že asistent hledal odpověď v databázi, místo vyhledávače a jindy zase nereagoval ohledně předchozí komunikace. Ale je to spíše věc dobrého promptu a nastavení podmínek pro spuštění daných akcí. Když jsem správně specifikoval a upřesnil otázku, tak jsem se správné odpovědi dočkal.




