
Toto je seriál, kde ukazuji vývoj vlastního AI/LLM chatbota. Něco jako free chatGPT na vlastních datech. V tomto dílu vám ukážu, jak jsem do aplikace přidal databázi Arxiv pro vyhledávání odborných článků z oblasti fyziky, matematiky, informatiky, kvantitativní biologie, kvantitativních financí, statistiky, elektrotechniky a systémové vědy a ekonomie.
Dalším užitečným nástrojem, který jsem chtěl přidat, je databáze Arxiv. Je to také mimochodem databáze, kde najdete spoustu odborných vědeckých prací na téma strojové učení – tedy AI.
K přístupu do databáze jsem použil framework phidata, který umožňuje pomocí asistentů přístup do databáze a následné uložení do vektorové databáze. Díky tomu můžeme vyhledávat jednotlivé studie na dané téma a následně se doptávat na detaily textu, vytvořit shrnutí a získat odkaz na původní zdroj z arxiv.
Arxiv asistent
Má na výběr následující komponenty:
- Vyhledávání v databázi Arxiv
- Uložení dat do databáze
- Možnost dotazování na daný text z Arxiv
- Propojení s LLM pro zpracování textu
Asistent nejprve vyhledá informace v databázi Arxiv na základě uživatelského dotazu. Tato data stáhne a uloží do znalostní báze. Následně získáme odpověď ze znalostní báze a asistent vypíše stručný přehled + odkaz na primární zdroj Arxiv.
Technologie
Chatbot obsahuje následující komponenty:
- Streamlit – webové rozhraní
- Databáze Postgres a Pgvector
- Phidata – Framework, který umožňuje LLM asistentům přidat paměť, znalosti a nástroje
Nástroj obsahuje jen základní komponenty. Šlo mi o jednoduché a velmi rychlé nastavení.
Uživatelské rozhraní
Testování
Zkusíme několik příkladů dotazů.
Show me studies about LLM RAG.
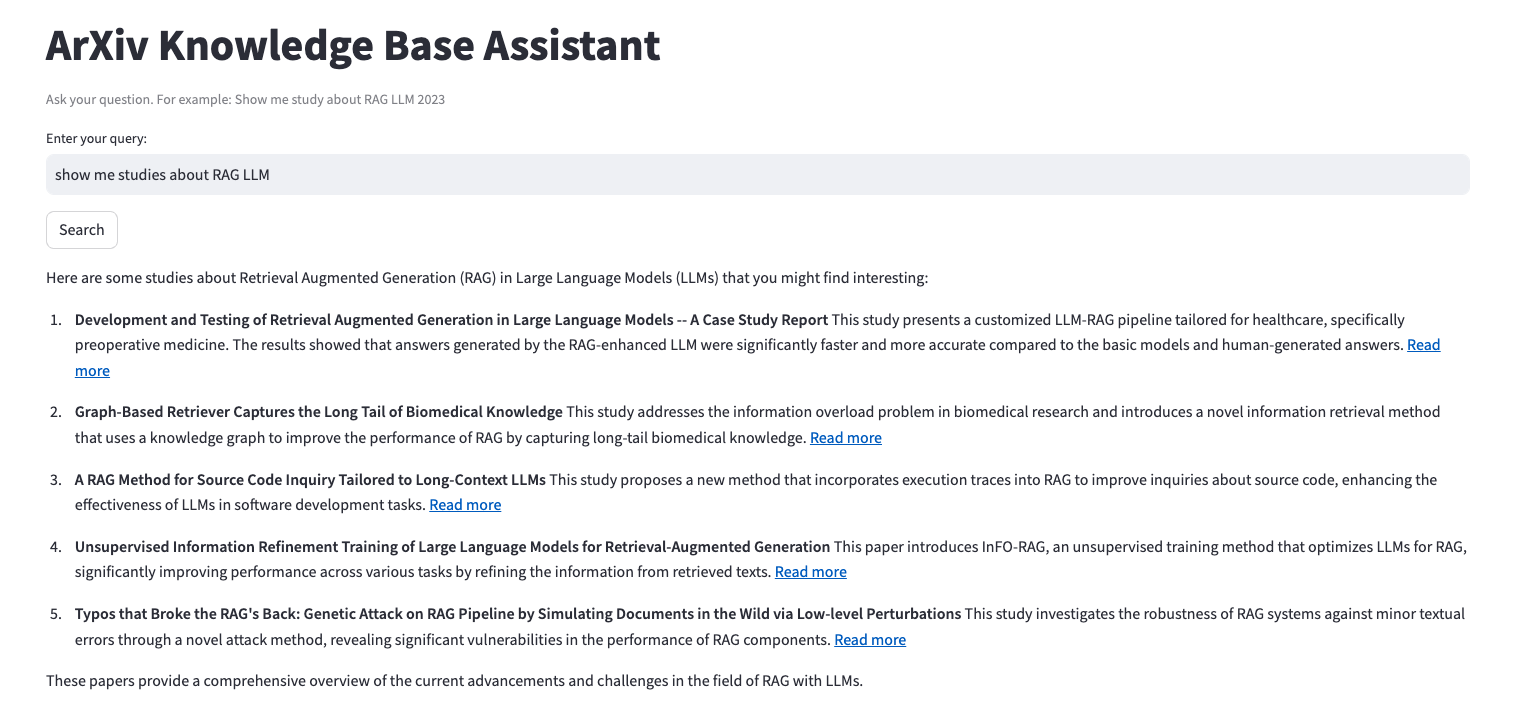
Můžeme si i kliknout na odkazy a otevřít jednotlivé studie.

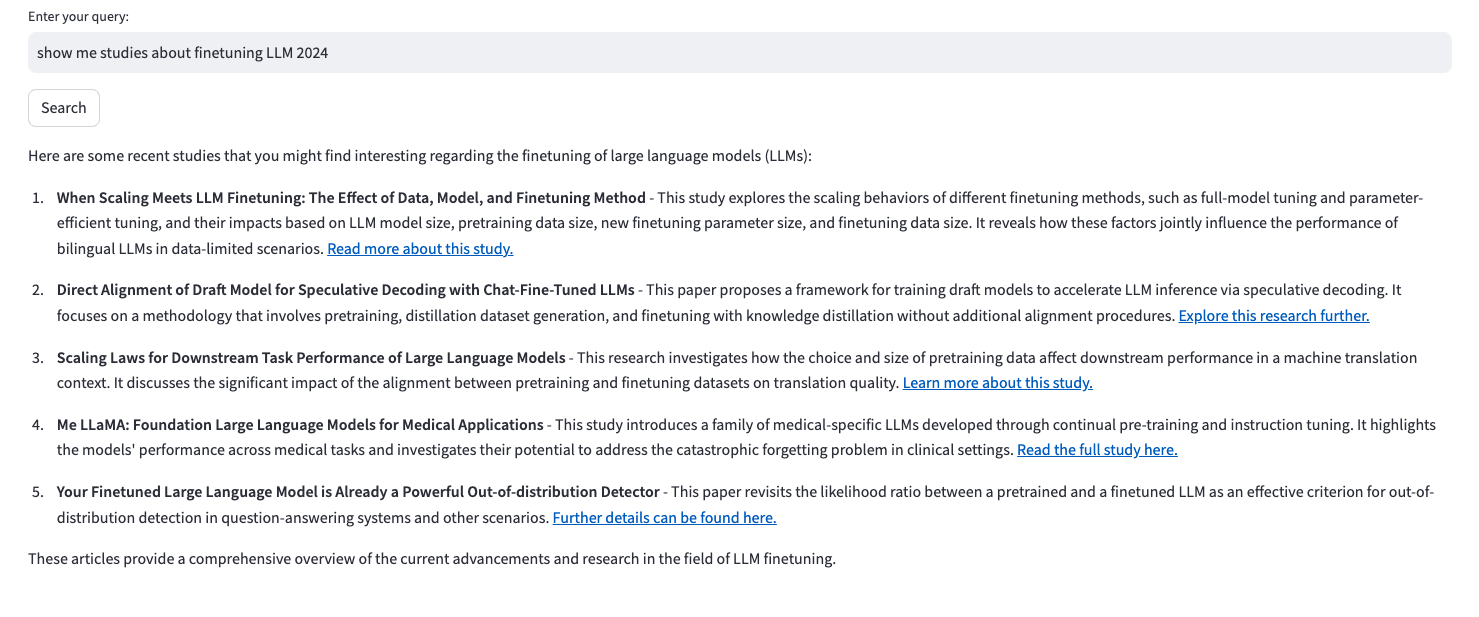
Show me studies about finetuning LLM 2024.
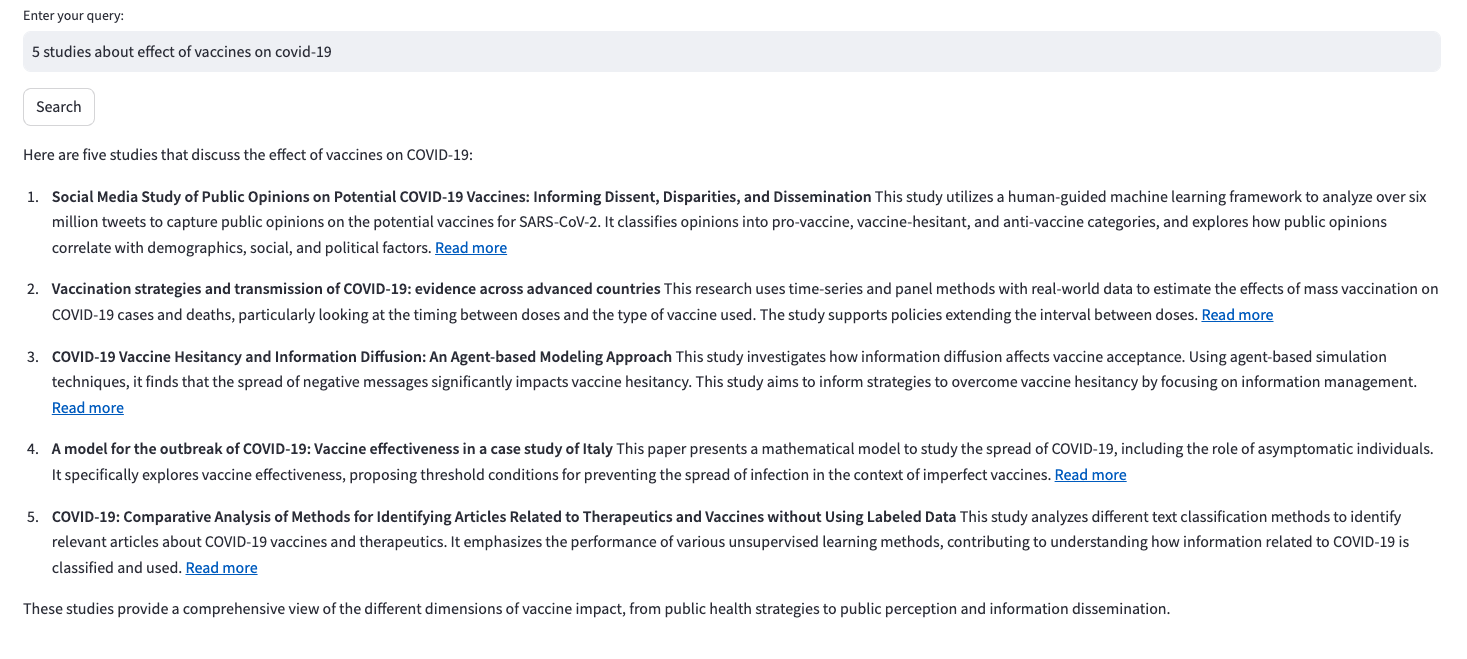
5 studies about effect of vaccines on covid-19.
Find me studies on a new cancer treatment approach.
(zde jsem získal i odkazy přímo na pdf daných studií)
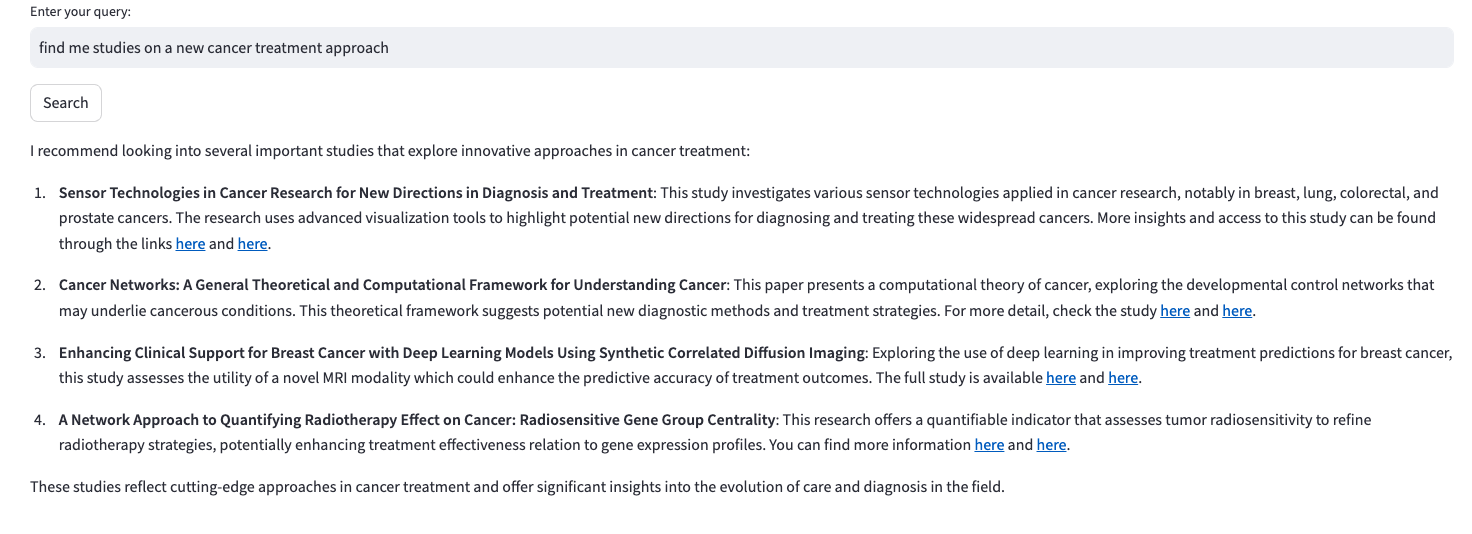
Detail jedné studie.

Co bych vylepšil
Zatím jsem zkoušel jen toto jednoduché rozhraní. Pro příště bych přidal některé komponenty pro zlepšení:
- Přidání více databází, kromě arxiv např. pubmed nebo google scholar
- LLM model Llama 3 + Groq
- Lepší zpracování pomocí RAG a následné dlouhé souhrny
- Zvýšit rychlost a počet výsledků
Jakmile budu mít toto řešení naprogramované, přidám jej do tohoto seriálu.



