

V následujícím SEO seriálu postupně procházím jednotlivé aspekty SEO a dávám tipy, jak zlepšit viditelnost a nalezitelnost vašeho webu ve vyhledávačích.
V tomto dílu si projdeme technickou stránku webu a její správné fungování.
Máte zájem o službu SEO – optimalizace webu?
Neváhejte mně kontaktovat.
Předpokladem fungujícího webu je to, že váš web funguje správně i technicky. Co to v praxi znamená?
Z hlediska SEO nás zajímá zejména:
- Indexování a robots.txt
- Funkční url
- https
- Správně vyplněné meta popisy
- Rychlost načítání
- Responzivita
- Duplicity
- Crawl budget
- Strukturovaná data
- Jazykové mutace (hreflang)
Technickou stránku vašeho webu můžete kontrolovat s pomocí nástroje Search Console od Google. Neboť pro Google je vždy žádoucí, aby váš web fungoval správně a vy jste znali důvod případných problémů.
Indexování a robots.txt
Pokud chcete, aby se váš web zobrazoval ve vyhledávačích, je potřeba umožnit přístup indexovacímu botovi.
Obvykle není nutné nějak extra specifikovat, že je přístup pro roboty povolen. Protože pokud tato specifikace sama o sobě není, tak je přístup automaticky povolen.
Musíte však zkontrolovat, zda není z nějakého důvodu přístup naopak blokován. Může se to stát, pokud váš vývojář indexování dočasně zablokoval a zapomněl index status změnit.
Zákaz indexování může být stanoven buď v souboru robot.txt, nebo pomocí meta značky robots. Správně je to pouze v meta robots, rozdíl vysvětlím níže.
Robots.txt také např. definuje, které konkrétní částí webu neindexovat (např. přístup do admin).
Rozdíl mezi robots.txt a meta robots
Robots.txt se primárně nepoužívá na vyřazení stránek z indexu vyhledávače.
Je určen k zabránění požadavku robota na procházení některých částí: např. na soubory obrázků, videosoubory, soubory PDF a jiné soubory než HTML.
Pokud chcete zablokovat indexování html stránek v souboru robots.txt, tak se mohou stále zobrazovat v indexu, pokud na ně vedou nějaké odkazy z jiných webových stránek.
Naopak indexování lze zcela zablokovat pomocí značky meta robots. Lze i kombinovat „noindex“ a „nofollow“. Můžete zabránit procházení pro všechny vyhledávače, nebo jen pro Google (googlebot)
Příklad nastavení příkazu neindexovat obsah webu:
<meta name=“robots“ content=“noindex“ />
Pozor na případ, kdy blokujete přístup robotům v souboru robot.txt a zároveň v meta robots. Robot pak na stránku vůbec nepřijde a nezaznamená zákaz indexu z meta robots.
Protože pro něj není robots.txt v tomto případě určující, tak stránka může být dál indexována.
Funkční Url
Url vašich stránek by mělo být funkční. To znamená, že stavový kód stránky je 200 a je tedy úspěšně indexováno (To však ještě neznamená, že Google nezaznamenal jiné problémy).
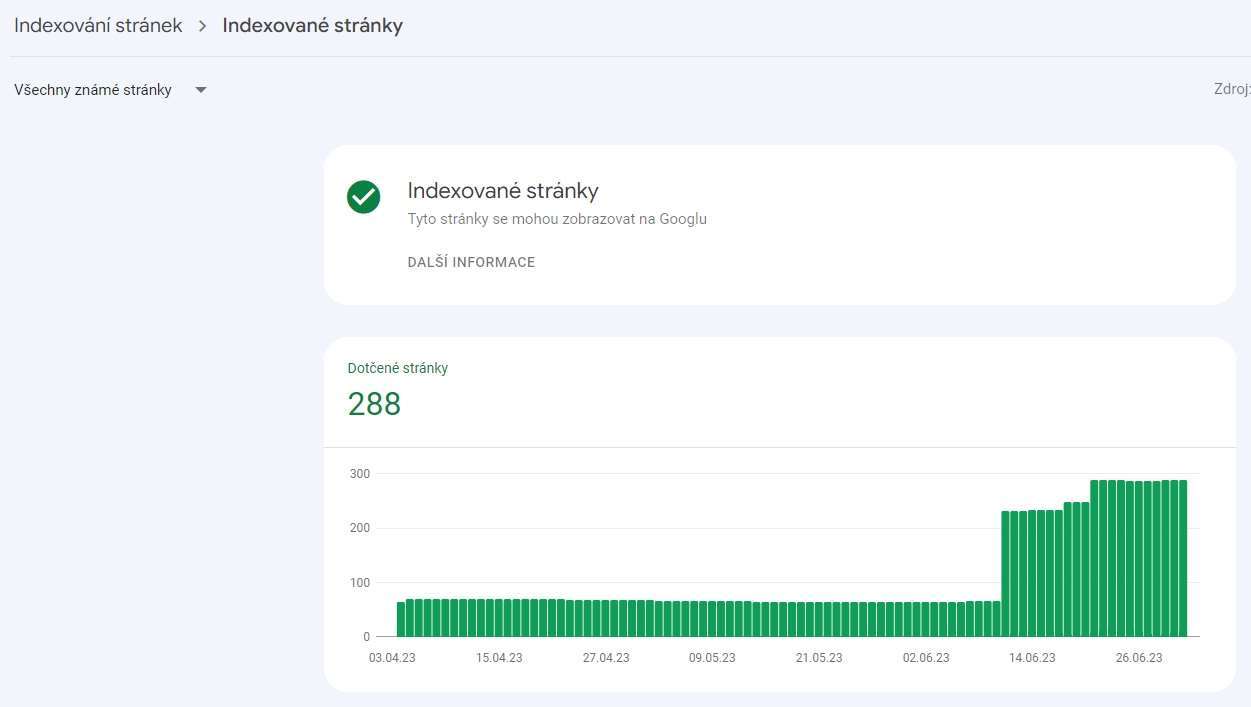
Jaké jsou další stavy a proč je Google nemusí indexovat:
Ne vždy to musí nutně znamenat chybu. Jsou i případy, kdy je to naopak žádoucí (trvalé přesměrování, kanonizace, atd.), dočasné řešení (dočasné přesměrování), nebo trvalé smazání stránky bez náhrady alternativy.
- Chyba serveru (5xx)
- Chyba přesměrování (příliš dlouhé přesměrování, nebo smyčka, atd.)
- Blokováno robots.txt
- Url označeno „noindex“
- Chyba 404 (stránka nenalezena)
- Blokováno neoprávněným požadavkem (401)
- Blokováno zákazem přístupu (403)
- Procházeno – momentálně neindexováno (možné přetížení severu)
- Alternativní stránka kanonické stránky
- Duplicitní stránka bez kanonické verze
- Stránka s přesměrováním
Doporučení pro tvorbu url adres
- Klíčová slova v url (bez diakritiky)
- Spíše kratší slova
- Lokalizovaná slova
- V případě potřeby kódování UTF-8
- Doména pro danou zemi
- Podadresář pro konkrétní zemi s gTLD
- Spojovníky (-)
Nedoporučuje se
- Použití jiných než ASCII znaků
- Nečitelná, dlouhá čísla
- Podtržítka
- Slova spojená dohromady
Https
Už je to nějakou dobu, co Google doporučil, aby všichni vlastníci webů přešli na bezpečnější protokol https. Protokol HTTPS je stejný jako HTTP, jen navíc dává prohlížeči pokyn, aby šifroval data přenesená z webové stránky.
Doporučuji u nových webů rovnou zakládat s protokolem https a u protokolu http trvale přesměrovat 1:1 na https verzi.
Https se dnes již bere jako standard, proto nebudu ani více rozepisovat.
Správně vyplněné meta tagy
Rozlišujeme následující meta značky stránky (nutné umístit do sekce Head):
- Title (výstižný název stránky do 60 pixelů)
- Description (může se stát, že Google vybere ale jiný popisek na základě obsahu)
- Robots
- Výsledky vyhledávání podstránek
- Ověření vlastnictví
- Typ obsahu a znaková sada
A další.
Co naopak Google vůbec neřeší a ignoruje: Meta keywords – Nemá přínos pro uživatele ani již pro vyhledávač.
Na co se soustředit:
- Title – Krátký, výstižný, hlavní klíčové slovo (do 60 znaků)
- Description – Krátký popis, klíčová slova, důraz na zvýšení CTR (do 160 znaků)
Rychlost načítání stránek
Rychlost je důležitá pro uživatele i vyhledávač. Důraz je kladen na rychlé načtení obsahu, na uživatelský zážitek a okamžitou interakci s uživatelem.
V dnešní době rychlého internetu, je důraz rychlosti kladen především na mobilní zařízení, kde může být načítání pomalejší (než u běžného desktopu).
Rychlost načítání můžete zkontrolovat pomocí nástroje PageSpeedInsight.
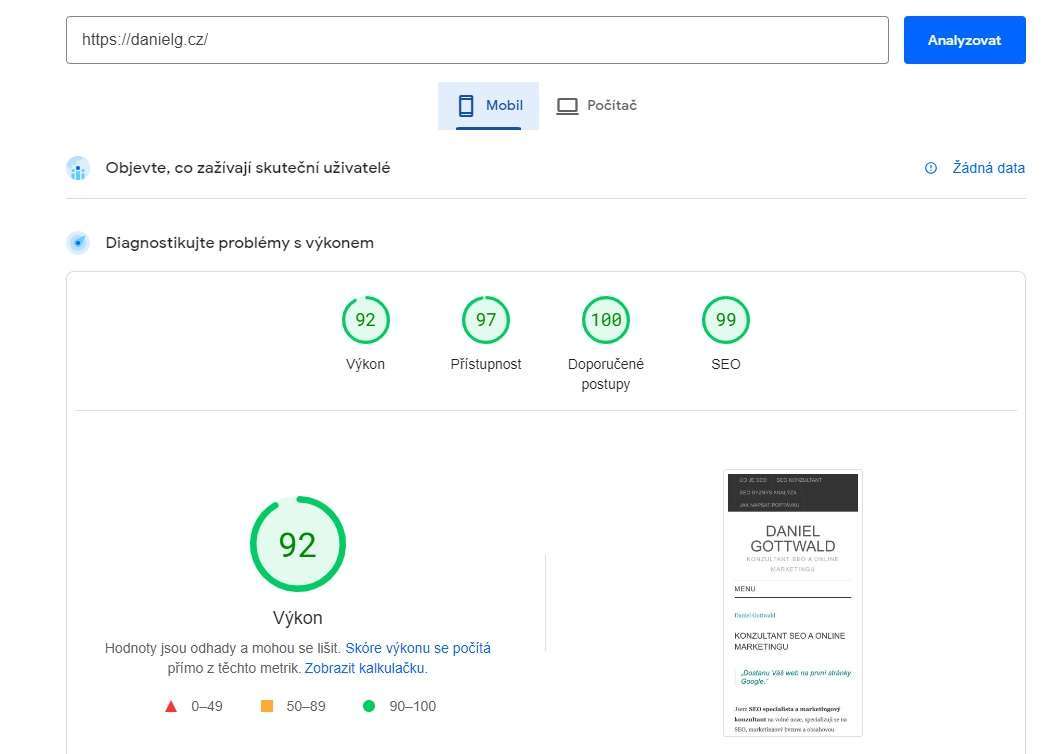
Konkrétní příklad zlepšení rychlosti načítání webu uvedu v samostatném článku.
Responzivita
V dnešní době má většina uživatelů internetu k dispozici chytrý telefon. Proto je nutné tomu přizpůsobit i samotný obsah webu. Zejména velikost jednotlivých prvků, různé funkce a interakci.
Cílem je, aby bylo procházení webu stejně snadné jako na desktopu, jen přizpůsobené specifickému typu interakce se zařízením (tj. typicky dotykové ovládání pomocí ruky).
Na co se zaměřit u mobilního vyhledávání
- Responsivní design (velikost a prvky přizpůsobené danému zařízení)
- Dynamické zobrazování (stejné url bez ohledu na zařízení)
- Obsah stejný na mobilu i ve webovém prohlížeči
- Stejné meta značky
- Stejná strukturovaná data
- Ohlídat si obrázky i videa (kvalita, popis, podporované formáty, strukturovaná data)
Konkrétní příklad úpravy webu uvedu v samostatném článku.
Duplicity
Duplicity mohou vznikat z různých důvodů:
- Různé url se stejným obsahem (klasicky http a https, bez přesměrování)
- Filtrování produktů, kde se zobrazuje podobný obsah
- Některé kategorie i produkty mohou mít stejné popisky (důvodem může být automatizované vyplňování dle názvu)
- Optimalizace na různé lokace s stejným nebo podobným obsahem
Jak to vyřešit:
- Trvalé přesměrování 301
- Kanonizace URL
- Kanonizace a paginace
- Psát pouze unikátní obsah, který se neopakuje
Co dalšího lze kanonizovat
- Varianty regionů
- Varianty zařízení (verze pro mobily a PC)
- Náhodné verze (demo, apod.)
Crawler budget
Pokud máte hodně stránek webu (tisíce až miliony), které se často mění, pak byste měli řešit i crawler budget.
Crawler budget je množství času a zdrojů, které Google věnuje procházení vašeho webu.
„Googlebot chce procházet váš web, aniž by zahltil vaše servery. Aby tomu zabránil, Googlebot vypočítá limit kapacity procházení , což je maximální počet souběžných paralelních připojení, která může Googlebot použít k procházení webu, a také časové zpoždění mezi načtením.“
Limity jsou nastavené podle
- Stav procházení (jak rychle váš web reaguje)
- Limit nastavený v Search Console (můžete nastavit sami)
- Limity Google procházení (omezené zdroje Google)
Co hraje roli při četnosti procházení
- Příliš mnoho duplicit, na kterých Google ztrácí čas procházením
- Popularita na internetu (návštěvnost, sdílení, CTR, atd.)
- Zastaralost (jak často vzniká nový obsah)
Strukturovaná data
Není přímo hodnotícím signálem, ale může pomoci s vyšším CTR.
Strukturovaná data jsou standardizovaný formát pro poskytování informací o stránce a klasifikaci obsahu stránky. Může se jednat např. o recenze, hodnocení, cenu, ingredience, doba vaření, atd.
Díky strukturovaným datům můžete více zvýraznit vaši webovou stránku ve vyhledávání a zvýšit tak CTR (množství lidí, kteří při hledání daného dotazu kliknou na odkaz).
Dále tím poskytujete informace s přidanou hodnotou hned ve vyhledávání.
Strukturovaná data se také zobrazují ve speciálních formátech Google: Např. v grafickém výsledku vyhledávání.
Vlastní strukturovaná data můžete nastavit pomocí průvodce Google.
U wordpressu je možné nastavit strukturovaná data pomocí pluginů, nebo přímo přes rankranger.
Konkrétní ukázku u svého webu uvedu v samostatném článku.
Jazykové mutace
Pokud máte na webu více jazykových mutací, určitě dejte pozor na nastavení Hreflang.
Kdy se doporučuje označit alternativy:
- Hlavní obsah v jednom jazyce a překlad pouze šablony (např. fóra)
- Malé regionální odchylky s podobným obsahem
- Obsah plně přeložen do různých jazyků
Obsah můžete označit pomocí:
- HTML
- http hlavičky
- Sitemap
Zmařit se můžete i na vícejazyčné a multiregionální stránky.
Toto byl takový krátký úvod do technického SEO. V příštích dílech se více zaměřím na konkrétní praktické tipy, jak vylepšit SEO stránek.
Jednotlivé díly seriálu
SEO tip 1) Technická stránka
SEO tip 2) Responsivní design
SEO tip 3) Rychlost načítání
SEO tip 4) Interní prolinkování
SEO tip 5) Kvalitní obsah
SEO tip 6) E-E-A-T
SEO tip 7) Odkazové portfolio
SEO tip 8) Klíčová slova
SEO tip 9) Videa
SEO tip 10) Obrázky
SEO tip 11) Webové příběhy
SEO tip 12) Google Discovery


